Explainable Artificial Intelligence for Authorship Attribution on Social Media
Abstract
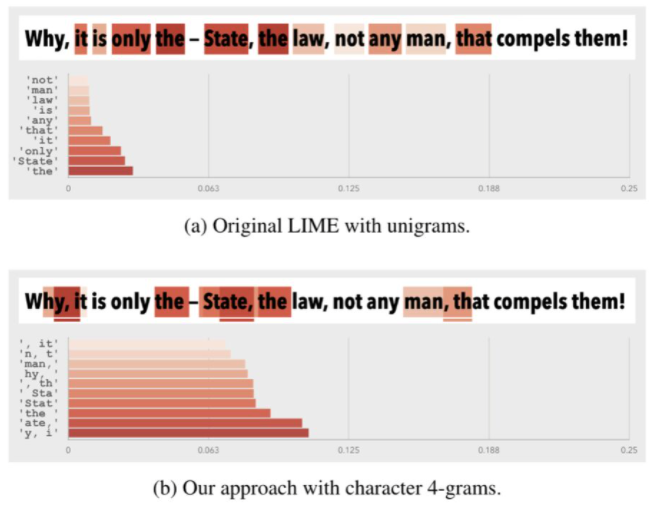
One of the major modern threats to society is the propagation of misinformation — fake news, science denialism, hate speech — fueled by social media’s widespread adoption. On the leading social platforms, millions of automated and fake profiles exist only for this purpose. One step to mitigate this problem is verifying the authenticity of profiles, which proves to be an infeasible task to be done manually. Recent data-driven methods accurately tackle this problem by performing automatic authorship attribution, although an important aspect is often overlooked: model interpretability. Is it possible to make the decision process of such methods transparent and interpretable for social media content, considering its specificities? In this work, we extend upon LIME — a model-agnostic interpretability technique — to improve the explanations of the state-of-the-art methods for authorship attribution on social media posts. Our extension allows us to employ the same input representation of the model as interpretable features, identifying important elements for the authorship process. We also allow coping with the lack of perturbed samples in the scenario of short messages. Finally, we show qualitative and quantitative evidence of these findings.
BibTeX
@inproceedings{theofilo22icassp,
author = "Antonio Theofilo and Rafael Padilha and Fernanda A. Andal{\'o} and Anderson Rocha",
title = "Explainable Artificial Intelligence for Authorship Attribution on Social Media",
booktitle = "{IEEE} International Conference on Acoustics, Speech, and Signal Processing ({ICASSP})",
year = 2022,
address = "Singapore",
}